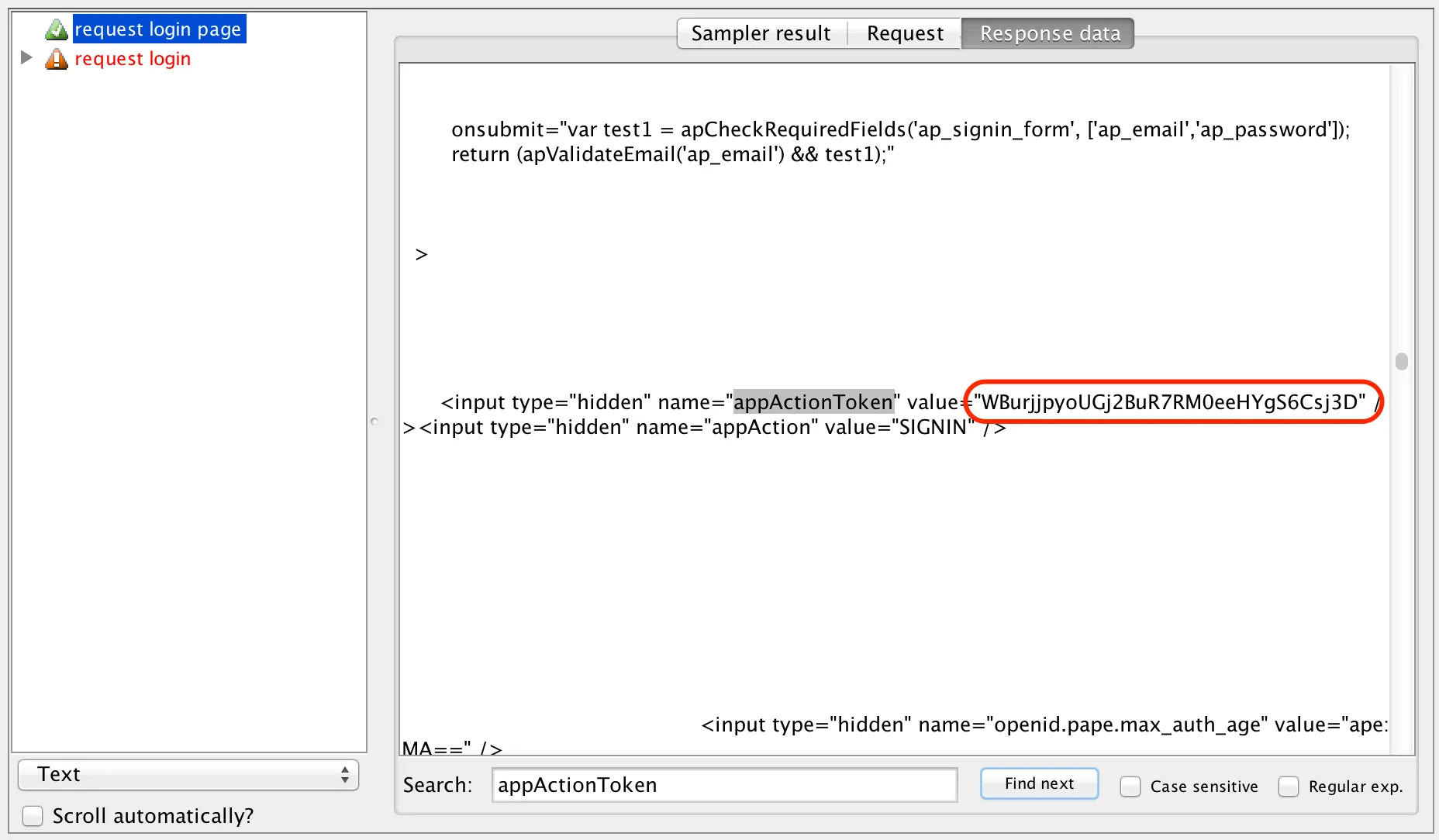
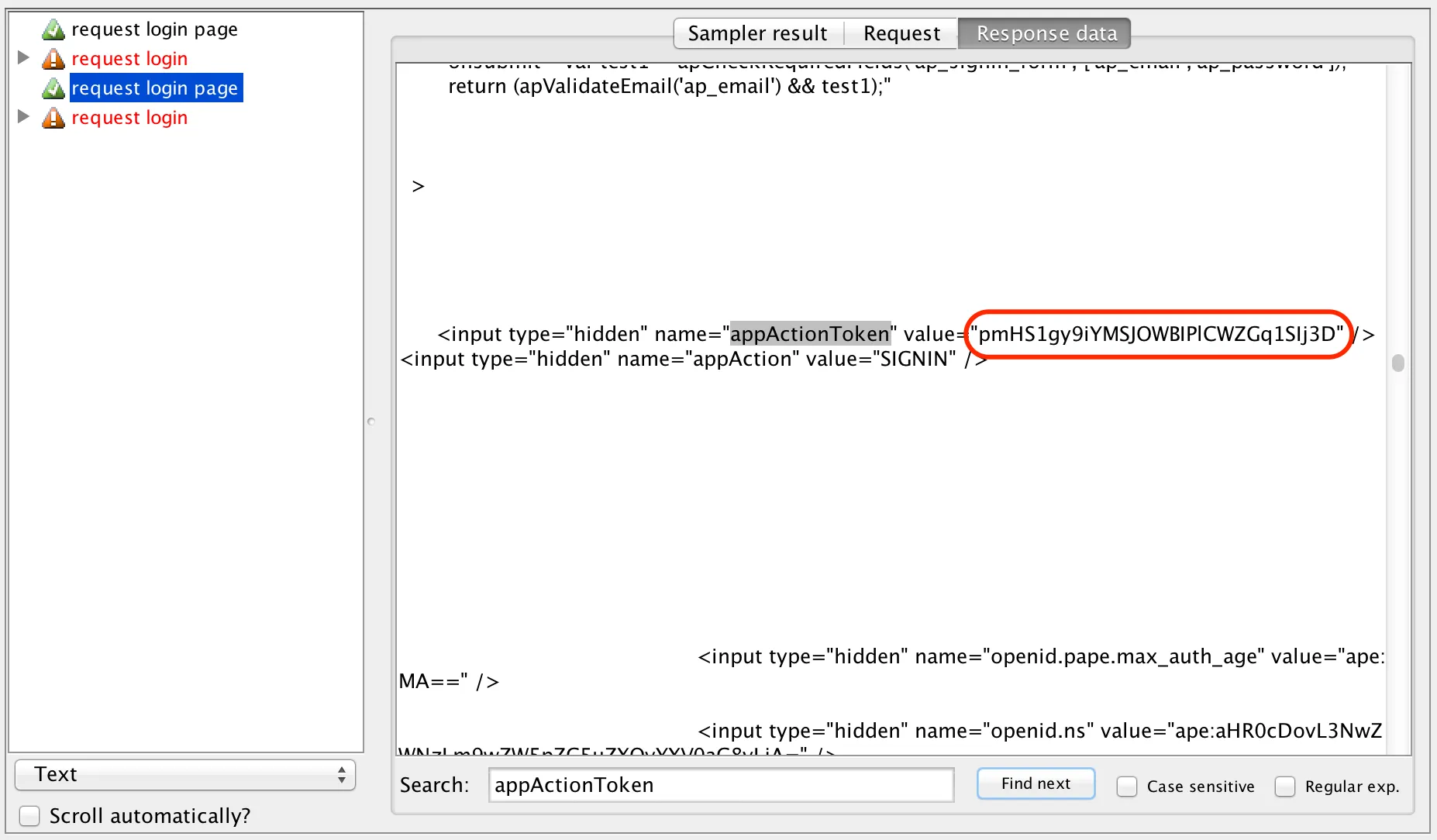
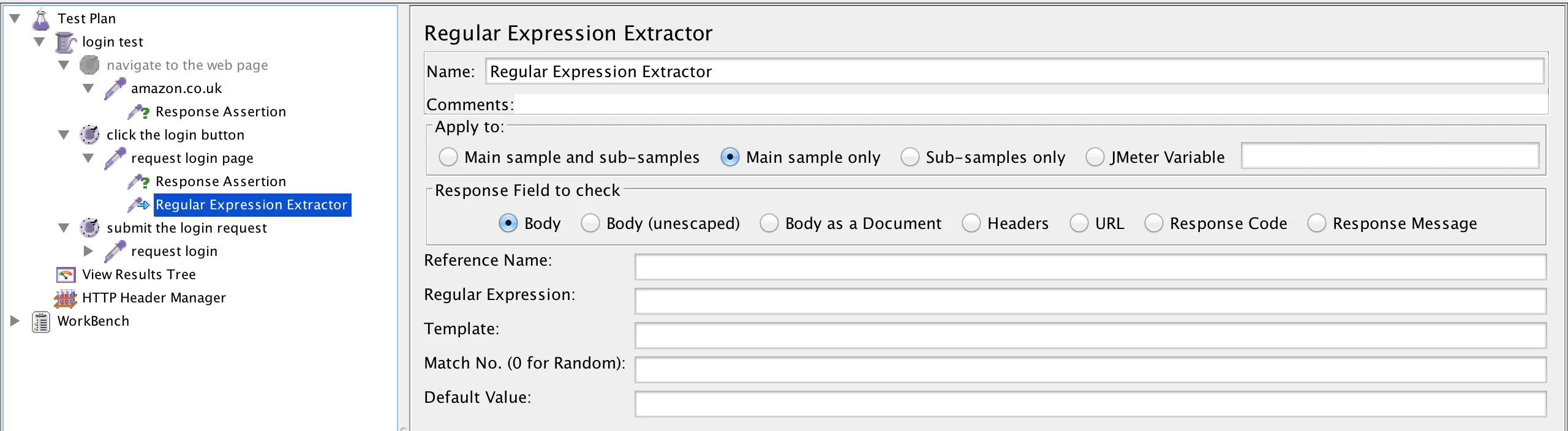
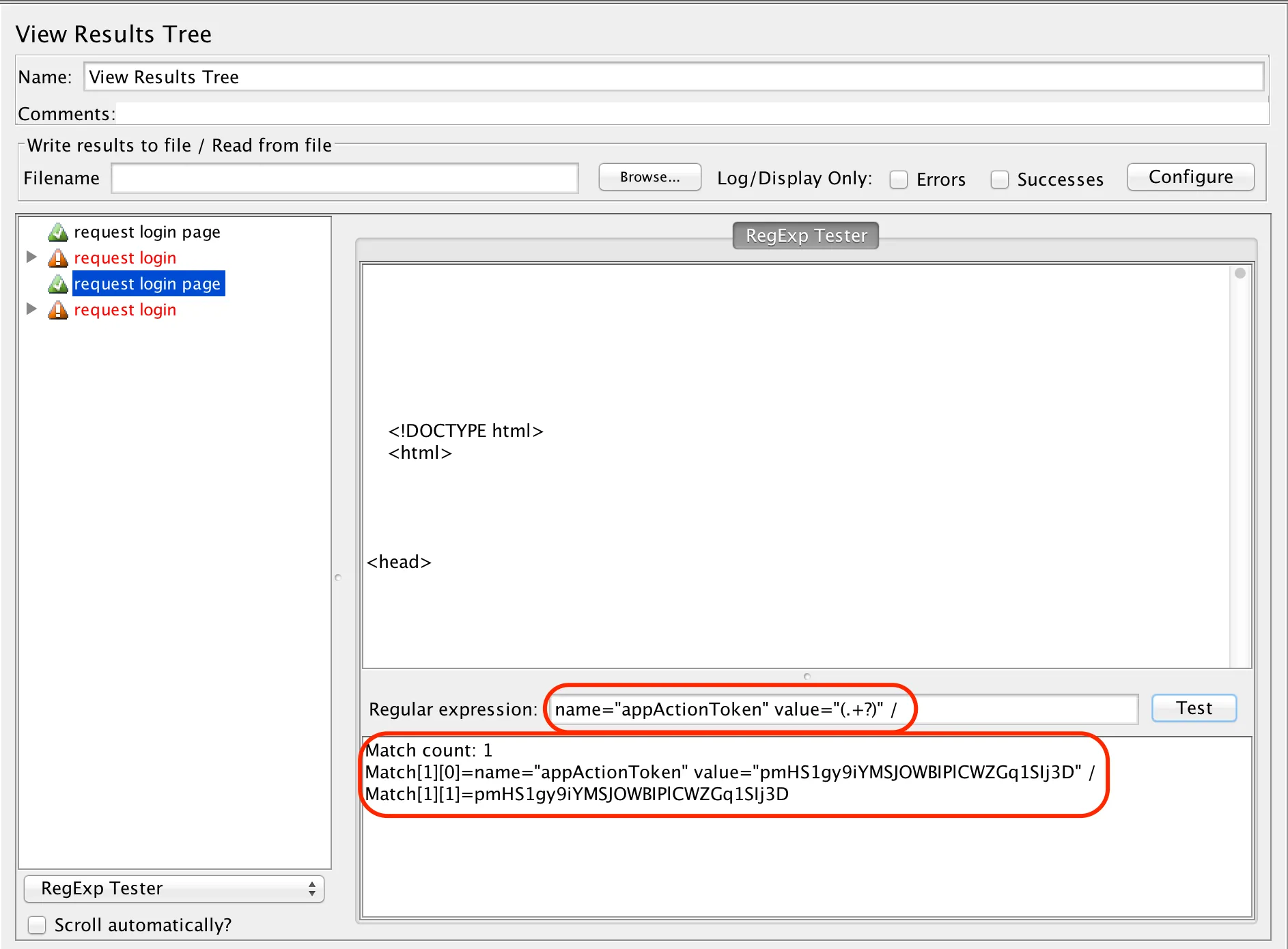
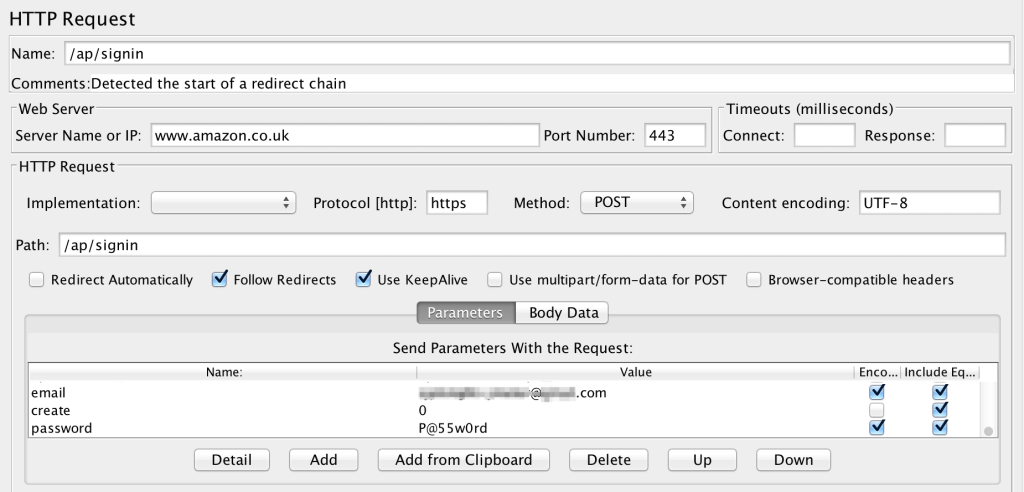
In my experiences of planning for testing in various different environments, and across a number of teams and organisations, the value of that planning was never the document itself; rather, it was the thoughts and consideration of the activities, resources and potential risks and issues yet to be discovered.
Thinking deeply about all of those things and writing them down, in whatever form the final document took, was the real value of the exercise.
Having those thoughts documented can of course be useful when you need to communicate the testing activities across a team of subordinates. It’s not quite so useful for communicating your intentions as they relate to testing activities to your stakeholders.
It’s far better to have those people in the room with you while you’re formulating your plan, so that they can provide you with the information you need to do that planning; and so that they have a say in the what, when, who, where, how of your test plan.
Pro-Tip: When writing a test plan, keep the 5 W’s front of mind: What, When, Who, Where, hoW.
- What will (and won’t) be tested? – The scope of your testing activities.
- How will it be tested? – The technical details of your testing; approaches, tools, environments, data, automation etc.
- Who will test it? – What human resources will you need to keep the testing on track?
- Why does it need testing? – Your rationale for committing time and resources to testing specific areas, over others. What are the risks to be addressed?
- When will testing start and finish? – What are the entry and exit requirements for your testing? How long will it take?
In ye-olde days of testing, I used to spend substantial amounts of time pulling together lengthy master test plan documents, in the region of 30-60 pages long (depending on the complexity of the project). Always with the sneaking feeling that they would probably not be read with the same amount of care I put into writing them.
Thankfully, with the ascent of more agile/lean ways of working, stakeholders have somewhat less patience for documentation of this nature. And they would often prefer and expect to be directly included in the planning process.
With that in mind, a leaner test planning and documentation mechanism is preferred. So I present to you 3x options for collaboratively documenting your test plan below.
Mindmapping Your Test Plan
I’ve found mindmapping generally to be an invaluable tool during the course of my software testing career. Whenever I have a problem or a piece of analysis to do, mindmaps – whether in digitial or notebook (pen & paper) form are my goto tool for exploring the problem space. And it’s the exploration of the test plan problem space that I’d happily recommend using a mindmap for also.
Here’s how I’d approach writing a test plan document in mindmap form, step-by-step;
[1] Start with a central node. What needs to be delivered? What is the outcome your stakeholders are looking to accomplish? This should form the locus of your testing efforts.
[2] From this central point, create branches for the other key components of your test plan:
- Testing scope – What will you address with your testing (in scope)? What will you not address (out of scope)?
- Timescale – When will the testing start & finish?
- Testing resources – Who will do the testing? What will they need? Where will they do it?
- Testing approaches – How will the testing be carried out?
- Risks & assumptions – What obstacles can you foresee? How will those be addressed?
[3] From those branches, drill down further into the various items and activities. For the scope, you can take the requirements, features or stories as being the next level down (sub-branches of the Testing Scope branch); and once you have those, you can drill further down into specific test cases, scenarios, exploratory sessions or whatever is needed depending on your preferred testing style.
[4] Do the same thing with all the other nodes and branches until you have enough detail for a test approach which stands up to some level of scrutiny from your stakeholders and team.
Pro-Tip: Don’t aim for perfection with your test plan. Whatever form it takes. Expect your stakeholders and team to probe the initial plan with some questions. You can update and revise it, and that process is much less painful if you haven’t already convinced yourself that the test planning is “done”. You should consider it a working document, subject to constant revision and updates based on the progress of your testing.
Once done, you will have ended up with a document that may look something like this, or completely different depending on the specifics of your approach and context. Either way is fine. As I mentioned earlier, the value of the test plan is in the planning (i.e. the thinking), not the document.
For super bonus points, you should create your mindmap collaboratively with the key stakeholders for the project or deliverable. Walk through all your thinking and rationale with them. Design the test plan together in a workshop. Give them the opportunity to add their own thoughts and ideas, and to buy into your approach as a result. The implementation and execution of your test plan will go more smoothly as a result.
Here’s a few more examples of mindmapping in the testing spaces:
The Single Page Test Plan
A similar approach is to use (or attempt) a single page test document.
In terms of content, you’ll probably find that taking this approach covers much the same ground as using a mindmap – since really; what is a mindmap other than a stylised set of indented lists?
Some people don’t like reading or looking at mindmaps though, finding them confusing or otherwise difficult to get their heads around. Using a simple one-page document addresses this objection, while keeping your test plan nice and lean still.
The scope of your document and the sequence of steps to be followed is virtually identical too:
[1] Identify the questions to be answered or addressed by your test plan (remember the 5 W’s). Use those as your section headers. You’ll probably end up with something like the following (looks familiar, huh?):
- Testing scope
- Timescale
- Testing resources
- Testing approaches
- Risks & assumptions
[2] Capture the necessary information on your document. Ideally in bullet point form, but provide further information (diagrams, models, tables etc) as needed.
You might (and in fact will likely) discover that your test plan doesn’t quite fit onto one page. Don’t worry about it. So long as the intention is to minimise the amount of extraneous information, you’ll be fine. Just make sure you capture the necessary information your stakeholders and testers need to enact the various items on the plan.
Pro-Tip: Use a text editor to capture the plan details rather than a formatting heavy tool like Word or Google Docs. Using a simple text editor and marking up your text will save space and preserve your intent to keep the doc down to a single page.
I’ve found that this is a good way to facilitate collaborative test planning as well. Get everyone into a room (virtually, or physically) and project or share the document you’re working on. Write the document as you’re collaborating. Capture the ideas of your entire team and any stakeholders in the room. Reflect their thoughts back to them as words on the page. If you follow this approach, you’ll start finding it very easy to get support from people, since the document contains their own words, as captured during your collaborative test planning session.
The Testing Canvas
Another iteration on the same line of thought is the testing canvas.
I’ve never been a huge fan of canvases personally, but they seem to have a lot of traction in the lean and agile worlds – so I’ll go along with it where necessary.
On the assumption that you have a fairly well defined set of sections for your test plan (such as the ones I’ve already mentioned a couple of times above), mapping those sections onto a testing canvas is a trivial task. Here’s a few examples to give you an idea of what I mean:
Again, the key benefit of following this kind of an approach is to provide a good mechanism for people to collaborate on the test planning. So, you could do this in several ways depending on what works best for your team:
- In a meeting room, using a white board to create the sections, and Post-It notes for the activities
- Create a spreadsheet with the various sections, and collaborate on that in a virtual space
Or you could use some other tools. Trello for example.
Test planning simplified
I’m a big fan of this quote from Helmut von Moltke:
“No plan survives first contact with the enemy.:
I especially like Mike Tyson’s version of the same truism:
“Everybody thinks they have a plan, until they get punched in the face.”
In the era of Modern Testing, you don’t need a lengthy test plan document to express your intent over the course of an iteration, or even an entire project. Most often, you just need to be sure you’ve identified what needs to be done, by when and whom, how it will be done and what resources you’ll need to do so.
More often than not, those ideas can be captured quickly and easily using a leaner form of documentation such as the ones above.
As I mentioned at the start of this article, the plan itself isn’t the important thing. It’s the thinking that goes into the plan that’s important. The plan itself is at best an intermediary document capturing a statement of intent from a specific point in time. It will almost certainly change as the project evolves and more information surfaces.
Rather than creating a huge document which goes out of date almost the moment it is completed, focus on the creation of smaller, leaner pieces of documentation which can more easily be updated when needed.
And above all, collaborate. All of the approaches I mentioned above can be used to facilitate meaningful collaboration between the person(s) responsible for steering the test effort, and the people with a deep interest in the outcome of that effort.
What’s more, using mindmapping tools in particular work very well in the online meeting space – since people can very clearly see the mindmap evolve during the course of a discussion. The same can be said of the one-page plan and the testing canvas, but the mindmap is a much more visual tool. Using something like XMind for example will give you the ability to demonstrate relationships between various items in the plan quickly and easily, and to call them out using graphical elements.